
1. Shell概述
Shell是一个命令行解释器,用于接受应用程序/用户命令,然后调用操作系统内核;Shell还是一个功能相当强大的编程语言,易编写、调试且灵活性强。
Linux提供的Shell解析器有多种:
1 | [root@hadoop100 ~]# cat /etc/shells |
sh 是 bash 的软连接;CentOS默认的解析器是 bash,可以通过 echo $SHELL 查看环境变量
第一个Shell脚本:
1 | [root@hadoop100 ~]# touch hello.sh |
脚本一般以 #!/bin/bash 开头:指定解析器
脚本常用的执行方式:
方式一:
1 | bash/sh 脚本的相对路径或绝对路径 |
此方式不需要赋予脚本可执行权限(x)
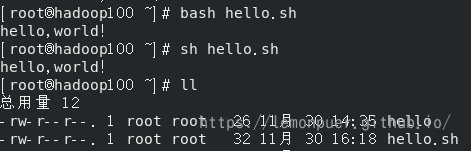
方式二:
采用输入脚本的绝对路径或相对路径执行脚本(必须具有可执行权限)
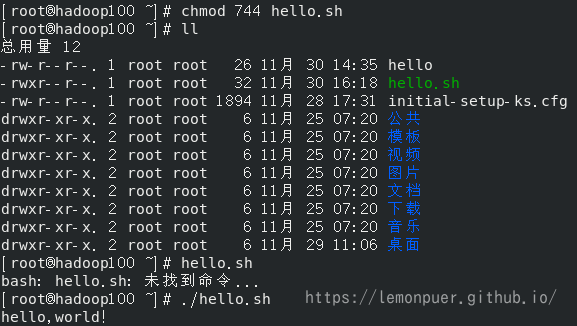
在目录使用相对路径时,不能直接输入名字,会当成命令执行
方式三:
在脚本的路径前加上“.”或者 source
1 | ./source 脚本路径 |
前两种方式都是在当前 shell 中打开一个子 shell 来执行脚本内容,当脚本内容结束,则 子 shell 关闭,回到父 shell 中。在脚本路径前加“.”或者 source 的方式,可以使脚本内容在当前 shell 里执行,这也是为什么我们每次要修改完/etc/profile 文件以后,需要 source
开子 shell 与不开子 shell 的区别就在于,环境变量的继承关系,如在子 shell 中设置的当前变量,父 shell 是不可见的
2. 变量
系统预定义变量
1 | 常用系统变量:$HOME、$PWD、$SHELL、$USER 等 |
自定义变量
定义变量:变量名=变量值,注意,=号前后不能有空格
撤销变量:unset 变量
声明静态变量(只读变量/常量):readonly 变量,注意:不能 unset
把变量提升为全局环境变量:export 变量
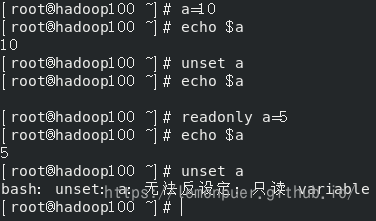
在 bash 中,变量默认类型都是字符串类型,无法直接进行数值运算;如 a=1+2 是以字符串的形式存储
变量的值如果有空格,需要使用双引号或单引号括起来;
变量定义规则:
- 变量名称可以由字母、数字和下划线组成,但是不能以数字开头,环境变量名建议大写。
- 等号两侧不能有空格
特殊变量
- $n
$n (功能描述:n 为数字,$0 代表该脚本名称,$1-$9 代表第一到第九个参数,十以上的参数需要用大括号包含,如${10})
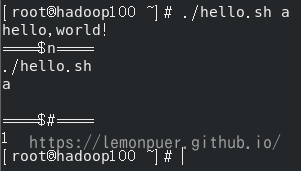
1 | [root@hadoop100 ~]# ./hello.sh a |
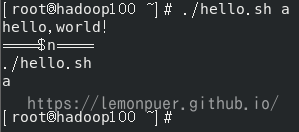
单引号不解析内部内容;双引号会解析。没有输入的参数没有输出
- $#
$# (功能描述:获取所有输入参数个数,常用于循环,判断参数的个数是否正确以及加强脚本的健壮性)
1 | [root@hadoop100 ~]# ./hello.sh a |
- $*、$@
$* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体)
$@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)
$* 相当于将所有参数组合为 ‘a b’ 的字符串;$@ 可以看作将参数放到一个数组中
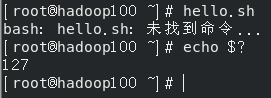
- $?
$? (功能描述:最后一次执行的命令的返回状态。如果这个变量的值为 0,证明上一 个命令正确执行;如果这个变量的值为非 0(具体是哪个数,由命令自己来决定),则证明 上一个命令执行不正确了。)
3. 运算符
Linux中特定的运算需要使用expr命令
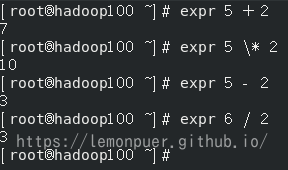
相当于向expr命令传输三个参数;其中*需要转义才能识别
当我们需要赋值给变量时,需要使用Linux中的命令替换(将一个命令的结果替换再进行操作)
1 | [root@hadpoo100 ~]# a=$(expr 5 \* 2) |
为了方便快捷的进行运算,我们可以使用Linux指定的运算符:
1 | $((运算式)) 或 $[运算式] |
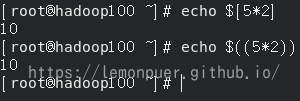
为变量赋值:
1 | [root@hadpoo100 ~]# a=$[(2+3)*2] |
5. 条件判断
1 | test 条件 或 [ 条件 ](注意 条件 前后要有空格) |
条件非空即为 true,[ atguigu ]返回 true,[ ] 返回 false。
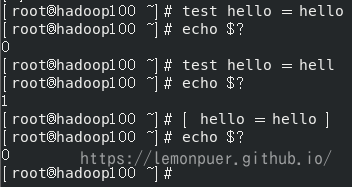
注意 = 两边需要空格,否则会被看作为一个字符串
- 两个整数之间比较
| 条件 | 功能 |
|---|---|
| -eq | 等于(equal) |
| -ne | 不等于(not equal) |
| -lt | 小于(less than) |
| -le | 小于等于(less equal) |
| -gt | 大于(greater than) |
| -ge | 大于等于(greater equal) |
可以用 “-z” 判断变量是否为空
如果是字符串之间的比较 ,用等号“=”判断相等;用“!=”判断不等。
- 按照文件权限进行判断
| 条件 | 功能 |
|---|---|
| -r | 有读的权限(read) |
| -w | 有写的权限(write) |
| -x | 有执行的权限(execute) |
- 按照文件类型进行判断
| 条件 | 功能 |
|---|---|
| -e | 文件存在(existence) |
| -f | 文件存在并且是一个常规的文件(file) |
| -d | 文件存在并且是一个目录(directory) |
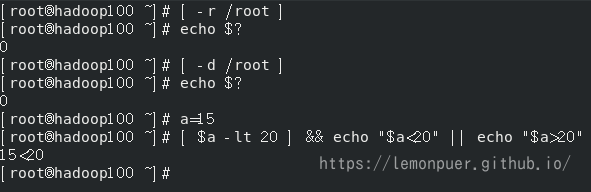
多条件判断(&& 表示前一条命令执行成功时,才执行后一条命令,|| 表示上一 条命令执行失败后,才执行下一条命令)
类似Java中的三元运算符
6. 流程控制
if 判断
- 单分支
1 | if [ 条件判断式 ];then 程序 ;fi |
Linux 中使用 ; 可以在一行执行多条命令
多条件判断:
1 | if [ 条件判断式 ] && [ 条件判断式 ] |
其中 -a :and;-o:or。
- 多分支
1 | if [ 条件判断式 ] |
if 后要有空
case 语句
1 | case $变量名 in |
case 行尾必须为单词“in”,每一个模式匹配必须以右括号“)”结束。
双分号“;;”表示命令序列结束,相当于 java 中的 break。
最后的“*)”表示默认模式,相当于 java 中的 default。
for 循环
语法一:
1 | for (( 初始值;循环控制条件;变量变化 )) |
在 (( )) 中可以直接使用数学上的运算符
1 | for ((i=0;i<$1;i++)) |
语法二:
1 | for 变量 in 值 1 值 2 值 3… |
此语法有点类似Java中的增强 for 循环

Shell 中 {} 表示一个序列,如 {1..100} 表示1到100
$* 和 $@ 的区别:
1 | #!/bin/bash |
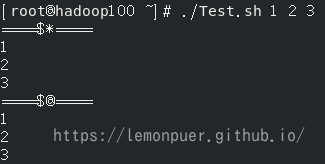
在不加双引号时,两者输出是相同的
1 | #!/bin/bash |
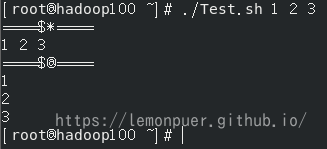
while 循环
1 | while [ 条件判断式 ] |
程序内部必须改变条件判断式的参数,否则会陷入死循环
1 | #!/bin/bash |
为了代码方便书写,Shell 添加了 let 命令可以使用其它编程语言的语法
读取控制台输入
1 | read (选项) (参数) |
-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒)不加表示一直等待参数:指定读取值的变量名
1 | #!/bin/bash |
7. 函数
系统函数
- basename
1 | basename [string / pathname] [suffix] |
basename 命令会删掉最后一个(‘/’)及之前的字符,然后将字符串显示出来。basename 可以理解为取路径里的文件名称
suffix 为后缀,如果 suffix 被指定了,basename 会将 pathname 或 string 中的 suffix 去掉。
- dirname
1 | dirname 文件绝对路径 |
从给定的包含绝对路径的文件名中去除文件名 (非目录的部分),然后返回剩下的路径(目录的部分)。dirname 可以理解为取文件路径名称
1 | #!/bin/bash |
命令替换可以看作系统函数的调用方式
自定义函数
1 | [ function ] funname[()] |
其中 [] 中的内容都可以省略
shell 脚本是逐行运行。不会像其它语言一 样先编译,必须在调用函数地方之前,先声明函数。
函数返回值,只能通过$?系统变量获得,如果不加,将以最后一条命令运行结果,作为返回值。return 后跟数值 n(0-255)
1 | #!/bin/bash |
这样函数的返回值不会受到 $? 的限制,且返回值sum可以进行进一步计算
8. 文本处理工具
cut
cut 的工作就是“剪”,具体的说就是在文件中负责剪切数据用的。cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
1 | cut [选项参数] filename |
| 选项参数 | 功能 |
|---|---|
| -f | 列号,提取第几列 |
| -d | 分隔符,按照指定分隔符分割列,默认是制表符“\t” |
| -c | 按字符进行切割后加 n 表示取第几列,比如 -c 1 |
1 | #查看ip |
awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
1 | awk [选项参数] ‘/pattern1/{action1} /pattern2/{action2}...’ filename |
| 选项参数 | 功能 |
|---|---|
| -F | 指定输入文件分隔符 |
| -v | 赋值一个用户定义变量 |
1 | #搜索 passwd 文件以 root 关键字开头的所有行,并输出该行的第 1 列和第 7 列,中间以“,”号分割。 |
BEGIN 在所有数据读取行之前执行;END 在所有数据执行之后执行。
| 内置变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数(行号) |
| NF | 浏览记录的域的个数(切割后,列的个数) |
1 | #统计 passwd 文件名,每行的行号,每行的列数 |
awk 中如果前面很多空格,默认删除
发送消息
可以使用Linux 自带的 mesg 和 write 工具,向其它用户发送消息。
1 | who #查看所有用户 |

